
神经网络最核心的问题就是参数的训练问题,而反向传播算法(backpropagation algorithm)在当中起着关键性的作用,本文详细介绍了反向传播算法的原理,并提供了详细的数学推导过程。通过对算法背后数学原理的了解,可以对反向传播算法建立更为透彻的理解。
1、反向传播算法和梯度下降算法之间的关系
刚开始接触的时候,分不清楚梯度下降算法和反向传播算法之间的关系,还以为两者是解决同一问题的两种不同的算法。随着了解的逐渐深入,渐渐搞清楚了这两个算法之间的关系。在神经网络中,需要这两个算法相互配合、共同使用才能解决神经网络的训练问题。
上一篇文章《深度学习1:初识神经网络》中已对梯度下降算法的思想做了介绍,其基本思想为首先随机初始化参数的值,然后计算损失函数在这个参数点的梯度,然后让参数的取值向梯度的反方向运动,即能够最大化降低损失函数的方向前进,使得损失函数逐渐逼近极小值。如果损失函数非常简单,例如y=x**2,那么我们可以直接通过求导得到每一个点的梯度,但是在神经网络中,参数的数量可能极其庞大,可能达到几千、几万甚至几十万个,通过直接求导的方式变得不太现实,那么在这样的情况下,我们如何求得梯度向量呢?这个时候就要发挥反向传播算法的威力了,反向传播算法能够非常快速有效地求得梯度向量。所以梯度下降算法是一个框架性的算法,利用梯度来逐渐逼近极值,而反向传播是解决求梯度问题的一个算法。反向传播只是梯度下降算法框架下解决其中一个核心问题的算法,两者并不是并列的关系,不是处于同一层级的两个算法。
2、反向传播算法的基本思想
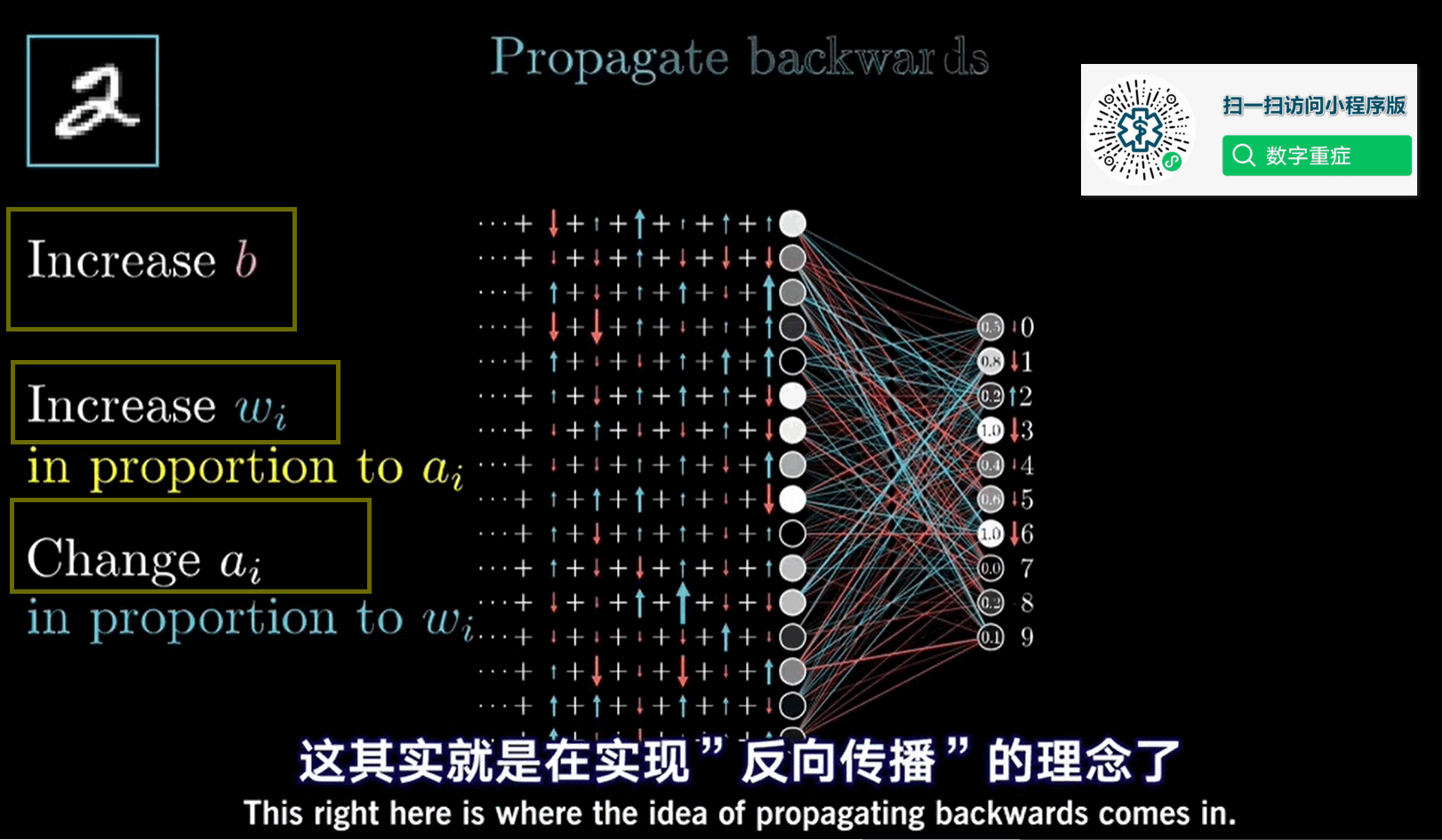
神经网络中有两次传播,一次是正向传播,一次反向传播。正向传播从第1层开始,逐渐向输出层传播计算的过程,解决的是根据输入值怎么求得神经网络的输出值的问题。而反向传播从神经网络的输出层开始,反向向第1层传播计算,解决的是求得每一层中各权重和偏差项参数的梯度问题。


(1)为什么要求各参数的梯度?
如果一个神经网络中有N个参数,那么神经网络参数的取值相当于N维空间中的一个点,模型训练的目的是在N维空间中找出一个最佳的点,使得神经网络能够最好地拟合训练数据。在梯度下降算法中,是从参数的随机取值开始的,即在N维空间中随机取了一个点,从这个随机的点开始,那么如何才能快速地找到我们所希望的那个最佳点呢?想象下,在3维空间,从一个随机的点出发,到我们希望找到的最佳点,这个路径是无穷多的,如果有没有一套方法来指导我们搜寻这个最佳点,那么效率将非常低,模型训练的时间将非常长。而梯度下降就是一个快速的搜寻规则,让参数取值始终往梯度的方向运动,使得我们能够以最高的效率在N维空间中搜寻到那个最佳的点。说清楚了为什么要求各参数的梯度,下面介绍如何来求参数的梯度。
(2)一个重要的中间变量
导数的定义是当自变量增加微小量时,函数的因变量会产生多大的变化,反映的是函数的变化速率。神经网络中求参数梯度的问题从数学上来说,其实就是对损失函数求各参数偏导数的问题。除了输入层神经元之外,所有神经元的输出都有下面这种形式,即对上一层的神经元的输出结果进行加权求和,并通过激活函数转化为自身的输出结果。变量z是上一层神经元输出结果的加权之和。变量a为以z为输入,是经过激活函数转化之后的输出结果。


我们来看一下,当变量z发生了微小的变化的时候,会发生什么样的情况。例如在L层的第j个神经元中,增加了delta z的时候,由于该神经元的输出结果会传导到下一层,层层传导下去之后直到传导到输出神经元。变量z的微小变化会导致损失函数的相应变化,我们把这个变化量定义如下:

δ是对变量z求偏导的结果,反映的是当变量z发生微小变化时,会给损失函数带来的变化量。如果δ为正,表示变量z的增加会导致损失函数结果的增加,代表模型的误差越来越大;如果δ为负,表示变量z的增加会导致损失函数结果的减少,代表模型的误差越来越小,这是我们希望得到的结果。
(3)反向传播的规则
下面是反向传播算法中四个重要的公式,提供了计算各层参数的方法。这里先不要陷入细节,先不要去管他这四个公式是怎么算出来的(会在下一节中详细说明每一步的数学过程),我们首先对反向传播算法建立起总体上的认识。第一个公式说明了第L层(最后一层)中间变量δ的计算方式。从公式2和公式3可以看到,根据变量δ,可以直接得到该层的误差项参数和权重参数的偏导数,可见变量δ是一个很重要的中间变量。从公式4可以看到,在知道了L层的变量δ值之后,则可以反向计算得到L-1层的变量δ,从而又可以根据L-1层的变量δ值,得到L-1层的权重参数和偏差项的偏导数,再得到L-2层的变量δ值,这样不断向前回溯,就可以得到神经网络所有参数的偏导数,即梯度。

公式4表示的本层的δ值与下一层δ值之间的关系,这种反向计算的关系我想就是反向传播算法这个名字的由来吧。刚开始接触反向传播算法的时候,有人介绍的时候说误差会在神经网络模型中反向传播回去,当时很不理解误差怎么可能会传播回去呢。其实误差并没有真的在神经网络中传播,而是上一层的δ值与下一层δ值之间存在这种数学关系,所谓误差的反向传播就是对这种反向计算方式的形象表达而已。
3、反向传播算法的数学推导过程
假设有一个总共包含L层的神经网络,每一层有若干个神经元,每一层的神经元都是全连接的关系,经过网络的前向传播之后,L层(输出层)的每一个神经元会得到最终的结果Ajl,如下图所示:

假设损失函数采用均方误差函数的话,那么在某个样本数据的损失函数为:

a. 计算最后一层(L层)参数的偏导数
首先来求中间变量Zjl的偏导数,根据链式法则,可以得到:

到此,神经网络最后一层涉及到的参数全部得到求偏导的结果,下面开始反向传播的过程。
b. 计算倒数第二层(L-1层)参数的偏导数
从上面的推导过程中可以看到,我们只要知道了L-1层的δ值,就能够很容易地得到L-1层的权重和偏差项参数的梯度了。因此关键是如何得到L-1层的δ值。这里很重要的一点是L-1层的变量z的微小变化会通过网络传导到L层的每一个神经元,正是存在这种传导关系,才使得L的δ与L-1层的δ建立起了某种联系,详细的数学推导过程如下。


在得到L-1层的δ值之后,就可以运用前面相同的方法,来得到L-1层的权重参数和误差项参数的偏导数了。通过这种逐层回溯的方式,可以计算得到整个神经网络的参数梯度。

本文对反向传播算法的数学原理进行了一步步的推导,不得不说,反向传播算法是一个很精妙的算法,通过运用该算法,大大地加快了神经网络的训练速度。
本文荟萃自公众号: 陈永刚 超级进化,只做学术交流学习使用,不做为临床指导,本文观点不代表数字日志立场。
 微信扫一扫
微信扫一扫